
When working with big (or huge) dataframes, it might be convenient to create a new dataframe that contains parts of the original one which are selected based on variable names, specific columns or rows, values or ranges…
In this post, we will use the following “pseudo-huge” dataframe as an example:
[code language=”r”]
alpha <- c(1,2,3,4,5,6,7,8,9)
bravo <- c("a","b","c","d","e","f","g","h","i")
charlie <- c(TRUE, FALSE, TRUE, FALSE, TRUE, TRUE, FALSE, FALSE, FALSE)
delta <- c("high", "low", "high", "low", "low", "low", "high", "low", "high")
echo <- c(45,78,76,09,34,12,17,78,54)
huge.dataframe <- data.frame(alpha,bravo,charlie,delta,echo)
huge.dataframe
[/code]
and the corresponding dataframe is:
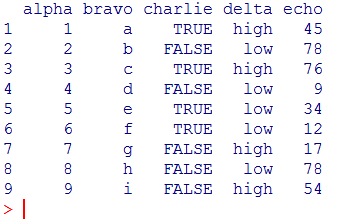
Playing with variable names and coordinates in the dataframe
Using df[x,y] where df is the name of your dataframe, you are able to indicate the coordinates of the rows and/or columns that you want to display. With df[x,] you will select for instance the rows x and all the columns while you discard the rest; using df[,y] you will select the column y and all the rows, while you discard the rest. Storing the result of this manipulation into a new vector thus creates a new dataframe with only what you have selected. Here are a few examples:
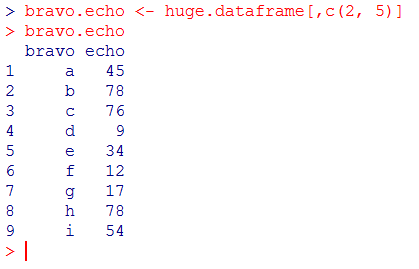
The following code reduces the dataframe to the columns named bravo and echo:
[code language=”r”]
bravo.echo <- huge.dataframe[,c("bravo", "echo")]
bravo.echo
[/code]

Note that since the columns named bravo and echo are the second and fifth columns respectively, it is possible to obtain the same result using their coordinates:
[code language=”r”]
bravo.echo <- huge.dataframe[,c(2, 5)]
bravo.echo
[/code]
Here is how you keep only a few selected rows and columns:
[code language=”r”]
bravo.charlie.secondrow <- huge.dataframe[2,c(2, 3)]
bravo.charlie.secondrow
[/code]

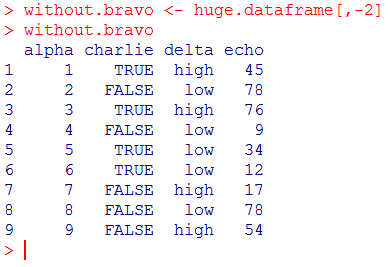
And if you are interested in removing rows or/and columns, you just have to indicate which and add a minus sign in front:
[code language=”r”]
without.bravo <- huge.dataframe[,-2]
without.bravo
[/code]
Working with subset()
The function subset() selects exactly what you wish to keep, as long as you are able to code it correctly. The syntax is subset(df, criteria) where df is the name of the dataframe from which elements will be extracted, and criteria is a formula that tells the function what to pick up in the dataframe. As you understand you can decide to keep rows and columns based on their content!
How to select out specific rows based on the value(s) of one of the variable?
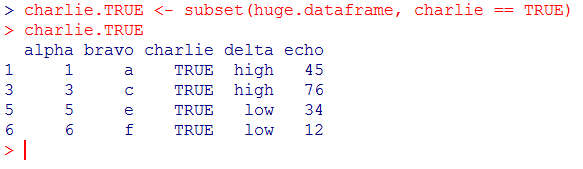
The following code shows how to pick only the rows (observations) for which charlie is TRUE:
[code language=”r”]
charlie.TRUE <- subset(huge.dataframe, charlie == TRUE)
charlie.TRUE
[/code]
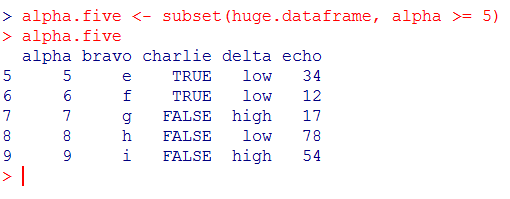
The following code shows how to pick only the rows (observations) for which alpha is greater than or equal to 5:
[code language=”r”]
alpha.five <- subset(huge.dataframe, alpha >= 5)
alpha.five
[/code]
How to pick rows based on the content of two variables (alpha is greater than or equal to 5 AND delta is “low”:
[code language=”r”]
alpha.five.delta.low <- subset(huge.dataframe, alpha >= 5 & delta == "low")
alpha.five.delta.low
[/code]
