dplyr and tidyverse (a larger package which includes dplyr) give the possibility to add columns (and thus variables) to an existing data frame. You may either add a new column from new data (usually based on the content of a vector, the content of another table or data frame, or simply from a simple series of numbers) or by computing new columns based on the content of one or several columns from the existing data frame (e.g. sum or mean of several variables located on the same row).
Here, we will review a few functions that allow for computing new columns based on the content of one or several columns from the existing data frame. You may read more about how to add new columns from new/external data HERE.
NB: some functions are part of dplyr but others are part of tidyverse. Should any of the following functions return an error message such as “could not find function …”, simply activate the package tidyverse using:
library(tidyverse)
These functions are:
Compute new columns with mutate()
mutate() is a function that produces a new column and fills it up with the transformation of an existing variable in the data frame. For instance, it may be used to multiply a variable by a factor, normalize it to a control value, obtain the log of the variable, etc.
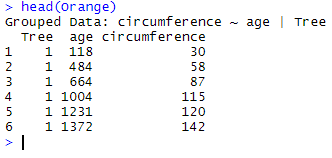
Let’s use the data frame Orange as an example. The top of the data frame looks like this:
head(Orange)
Here we want to add a column in which the data is the content of circumference multiplied by 10:
Orange %>% mutate(circumference*10)
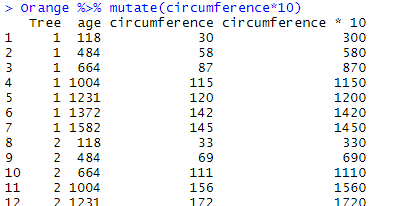
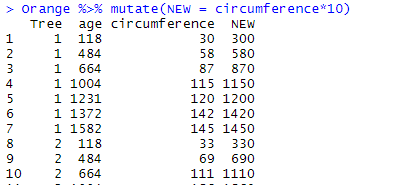
The new column is placed in the last position, and gets by default the “operation” as variable name. If we want to give a name to the new variable to be created, we can do so that way:
Orange %>% mutate(NEW = circumference*10)
Alternatively, we can do it in a second step with rename():
Orange %>% mutate(circumference*10) %>% rename(NEW = "circumference * 10")
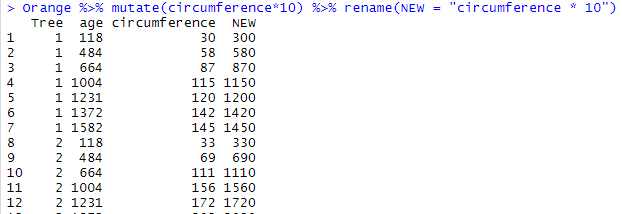
NB: note the particular syntax in rename(), where quotation marks are necessary, and spaces have been added on both sides of the symbol *.
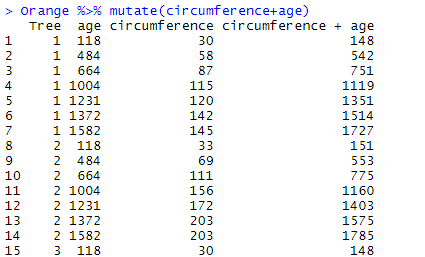
It is also possible to create a new variable based on the contents of several variables. Here we add the value of circumference to age (which does not make much sense, but illustrate well our case):
Orange %>% mutate(circumference+age)
Compute new columns and drop the old ones with transmute()
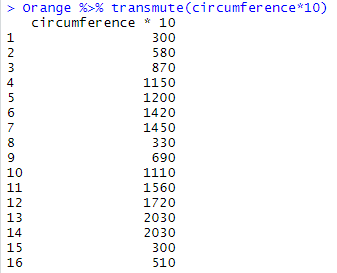
transmute() does the same as mutate() (produce a new column and fills it up with the transformation of an existing variable in the data frame), but it discards the original table in the output, and displays only the new, computed variable remains:
Orange %>% transmute(circumference*10)
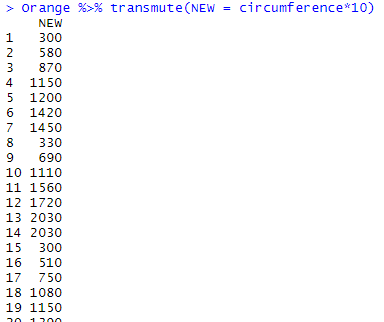
And again it is possible to give it a name beforehand:
Orange %>% transmute(NEW = circumference*10)