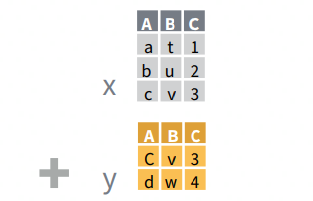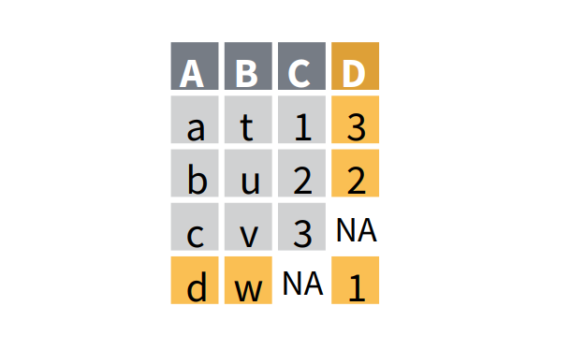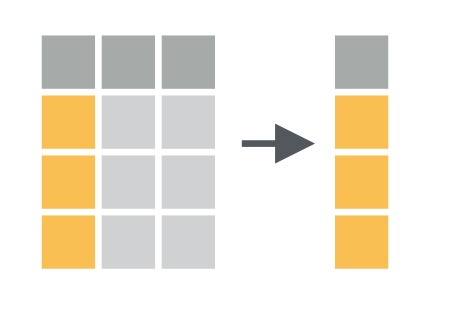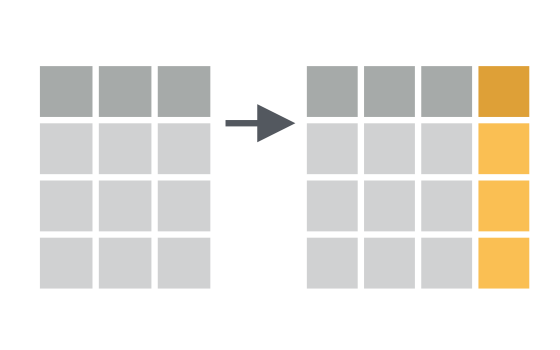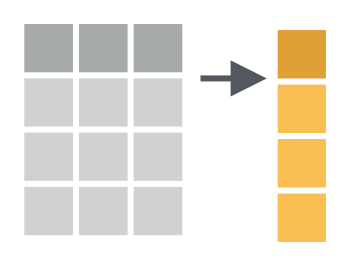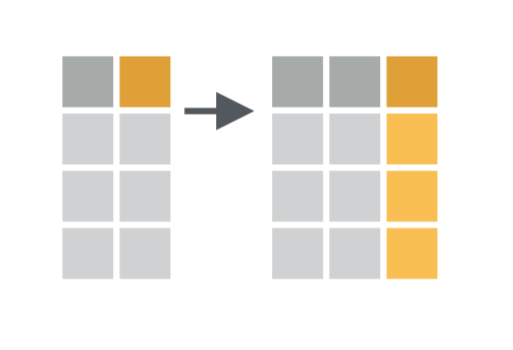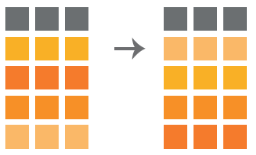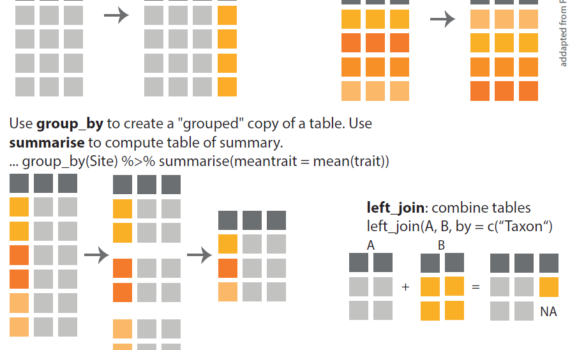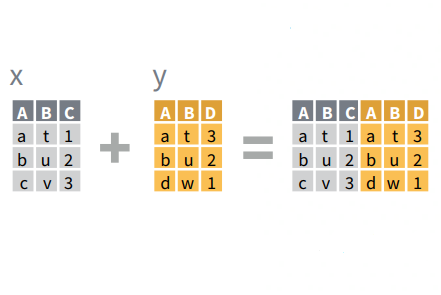
Entire data frames may be put together either beside each other (thus increasing the number of variables) or below each other (thus increasing the number of cases) into a single, large table. Here we focus on combining data frames beside each other. One of the functions that can do such […]