
Count() does exactly what it says: it counts the number of cases! Applied directly to a data frame, count() will provide you with the number n of cases. Applied to a table which has been pre-grouped with group_by() (read more about group_by() here) or in a pipe in combination with group_by(), it will give you the number of cases n for each group.
Let’s illustrate this with the data frame Orange:
Orange %>% count()
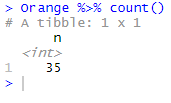
The table shows the single value 35 which matches the number of observations in the original data frame.
Let’s now see what happens when we apply it in combination with group_by():
Orange %>% group_by(age) %>% count()
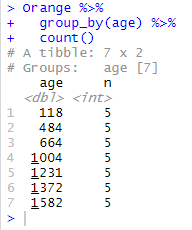
The result table shows indeed the number of observations for each factor of the variable age.
And the same happens when we apply count() to a pre-grouped table such as Orange_grouped_by_age:
Orange_grouped_by_age <- Orange %>% group_by(age) Orange_grouped_by_age %>% count()
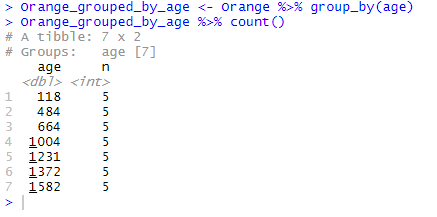
Finally, note that we may apply count() to a table where a variable is already organised in groups while specifying another variable between the parentheses of count(). In this case, the resulting table will show the number of cases for each of the combinations of variables. Let’s illustrate this again with the already-sorted table Orange_grouped_by_age and let’s apply count(Tree):
Orange_grouped_by_age <- Orange %>% group_by(age) Orange_grouped_by_age %>% count(Tree)
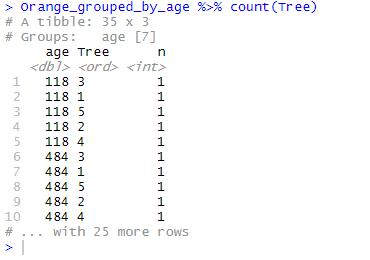
And indeed, the table shows that there is only 1 observation per age and per Tree.